本文由 GeneDock Genomic Data Engineer 成帆撰写,感谢 GeneDock 基因数据工程师孙兴强,武雅蓉,王玉梅在写作过程中的耐心地审阅和修改,转载请保留作者信息和出处。
小 F 是今年刚进入被誉为“没有疾病隐喻的乐土”的圣芒戈医院工作的一名生信分析师。能有幸为这样高水平的医院工作,小 F 心里美滋滋的。高兴了没两天,主任把小 F 叫去了:“小 F 啊,我听说你之前是专门做微生物二代测序数据分析的?你看,前阵子寨卡病毒传播这么猖獗,病毒的突变又这么厉害,你能不能结合现在大家测的这么多数据搞一个模型,帮我们分析这些疾病传播途径,同时对致病病毒的分子亚型也精确分类,看能不能提前控制疫情?”
小 F 一听就很激动,生平所学终于有了用武之地,两眼放光地对主任说:“您说的这些首先要基于对微生物参考基因组的标准重测序分析,然后根据 SNP 构建进化树, 这个构树方法,有一二三四五…”
主任大手一挥: “你说的这些技术细节我也不懂,你看着办吧。但这个标准重测序分析,前不久我跟咱们肿瘤科的张主任一起吃饭,他说了一个什么 GeneDock 的人类基因组的 HG 分析,一次只要 99,他们科室的人用过了都觉得简单易上手,结果还挺靠谱。反正咱们机房也还没到位,你要做就先看看你的微生物分析流程在这家云服务公司能不能跑吧。”
小 F :“得令!”
三天后。
小 F :“主任啊,GeneDock 这家是挺好。但张主任他们觉得好用,是因为他们科的人手上一星期可能也就几个病人样本,每次在浏览器里咔咔把数据路径一填就完事等结果了。可咱们这微生物尤其是流行病学的分析,那可得成百上千次分析啊,微生物变异又高,还得筛选模型,优化参数,我这细胳膊…”
张主任: “且为之奈——何——”(最近三国看得有点多)
小 F : “好消息是我发现他们有 Python SDK, 通过它,我就可以用代码配置工作流,批量投递任务。”
张主任:“听上去不错,那你练练?”
小 F : ”So easy! “
哪知道小 F 第一天就遇到了困难。
GeneDock Python SDK的安装
小 F 发现在 GeneDock 主站 可以直接下载该 Python SDK 的包,便急不可耐地下载了一个。

作为一个忠实的 linux 粉丝,伪重度命令行使用者的小 F 还用着研究生时代省吃俭用买的 mac pro 。轻车熟路打开了终端,看了看解压好的 genedock-official-python-sdk 文件夹中的内容,找到了传说中的安装必备
setup.py 。
在安装目录下敲下 sudo python setup.py install 回车,蹦出来的满屏的提示信息让小 F 心提到了嗓子,暗暗叫苦。每次解决安装过程中的包依赖或冲突问题什么的最闹心了。但仔细察看过程 log ,发现只是由于之前曾安装过一个 PyYAML 包,与 gdpy 需要的版本不一致,程序就帮忙重新安装了符合的 3.11 版本。所有的依赖包最后还是正确装上了。小 F 到 python 交互环境下验证了一下,没毛病!

万里长征第一步! Move on !
配置一个新工作流
小 F 发现 genedock-official-python-sdk/ 下面的 examples/ 目录中已经贴心的准备好一些程序脚本和配置文件的例子,粗略浏览后发现是一个用 fastqc 做数据质控的例子,决定先用它熟悉一下 SDK 的语法及相关概念。
之前主任让小 F 了解 GeneDock 时,小 F 已经学会了怎么在他们主站上运行一个工作流。lncRNA 是之前小 F 自己配置的一个工作流,如果添加成功,可以在个人帐号下查看到该工作流。而且“预设运行配置”和“运行”这些按钮都是活动的。第一次配置自己的工作流时小 F 经验不足,某些配置文件的字段填的不规范,这样配置的工作流帐号下虽然可以看到,但”预设运行配置”和“运行”这些按钮都是 inactive 的,并不能运行。
主站的界面可以很方便后期小 F 调试程序,查看效果。

初始化待创建工作流对象
小 F 决定先从用 SDK 配置一个 fastqc 的工作流开始。读完官方的 文档,把代码大致分为这么几步:权限配置 -> 创建一个 workflow 操作对象 -> 用 create_workflow() 方法在用户目前默认的 project 实例空间下创建一个工作流。
# -*- coding: utf-8 -*-
import gdpy
# 配置个人密钥信息,以访问主站资源时进行签名认证
access_key_id = '<从GeneDock主站个人帐号设置页面获得>'
access_key_secret = '<从GeneDock主站个人帐号设置页面获得>'
# 创建一个签名认证时需要的auth对象
auth = gdpy.GeneDockAuth(access_key_id,access_key_secret)
# 创建一个workflow对象
workflow = gdpy.Workflows(auth, 'cn-beijing-api.genedock.com', 'fancheng')
# 用create_workflow()方法新建一个工作流
create_workflow_result = workflow.create_workflow('Fantasy007', 1, 'my first boost')
将该段代码保存为 cfg_workflow.py , 命令行执行python cfg_workflow.py, 可以在个人帐号下看到刚创建好的该工作流。

看到 inactive 的“运行”按钮,小 F 傻眼了,急忙求助了帮助她申请帐号的 GeneDock 的 Y 大叔。
Y 大叔说: “ 小 F, 只用 create_workflow(), 这个工作流还不能运行。此时相当于我们只告诉了系统它的存在,但系统还不知道它调用什么软件?每个软件支持哪些参数?软件之间彼此调用的顺序是什么?可以接受几个文件作为输入?哪几步会有输出? 此时它在系统里还是不可执行的状态,咱们还不算完整地创建了它。“
小 F: “我懂了,Y 大叔,那我要怎么办呢?”
Y 大叔解释到 : “简单来讲,此时需要我们先写好一个 yaml 格式的配置文件,定义好这些内容,再利用 SDK 中的 put_workflow() 方法为新创建的workflow 增加定义,使之可以运行。”
为刚创建的工作流对象增加定义
见小 F 还是懵懵懂懂的样子,Y 大叔说: “要不我们看一下你正在试的这个 Fastqc 的工作流配置文件吧。”
小 F 说:“我知道 name 就是工作流的名称,例如我刚才创建的是 Fantasy007 ;version 是本次创建的工作流的版本,这是我第一次创建,就是1 ;description 是对工作流的一些说明,就是我刚才写的对 Fantansy007 的介绍,’my first boost’ 。其他的,尤其是nodelist这块, 一下子上来这么长一串,我就不知道了。”
Y 大叔: “不错,看来小 F 已经有一些了解了。nodelist 字段存储了组成该工作流的所有节点的信息。工作流中的一个节点可以理解为由一个或多个生信分析软件组成的数据处理单元。每个节点接收上游节点处理完成后的数据作为输入,在自身进行处理。这个处理过程,可以理解为执行一个生信软件中的一条命令,或连续执行多条命令,或调用一个自己编写的脚本,如文本处理或数据过滤筛选脚本。 每个节点计算完成的结果文件,会传递给下一个节点。”
# genedock-official-python-sdk/examples/workflow_put.yml
workflow:
account: public #需改为自己的帐号名
description: 工作流Fastqc #与create_workflow()中description 传入参数内容保持一致
name: Fastqc #与create_workflow()中workflow name 传入参数内容保持一致
nodelist:
- alias: 输入序列文件
...
...
...
- alias: fastqc 0.11.3
...
...
...
- alias: store Fastqc_output_tgz
...
...
...
version: 1 #与create_workflow()中version 传入参数内容保持一致
小 F 说:“ Y 叔,这次我懂了。这就好比以前,我会用一个perl脚本把几个顺次执行的相关的脚本串起来。就说微生物的重测序分析吧,在比对这一步,我把QC得到的clean reads与参考基因组比对的bwa mem命令和对生成的bam文件统计过滤的脚本封到一个perl脚本中了。这个脚本执行完后,就会生成bam文件和一个统计了mapped reads的文本文件。我的这个perl脚本,就相当于咱们说的节点。它接收上一步QC节点生成的clean reads 作为输入,生成了bam文件和统计结果文件作为输出。 ”
# 按工作流 Fastqc 的配置文件修改自己的 Fantasy007 工作流的配置文件
workflow:
account: fancheng # <== 改为自己的账户名
description: my first boost # <== 改为自己创建的工作流相关描述,会展示在网站上描述部分
name: Fantasy007 # <== 改为自己创建的工作流名, 会作为工作流标题展示
nodelist:
- alias: 输入序列文件
...
- alias: fastqc 0.11.3
...
- alias: store Fastqc_output_tgz
...
version: 1 # <== 改为自己创建的工作流的版本信息, 会作为右上角版本信息展
# 示
Y 叔:“ 小F 理解得很正确。上面nodelist 字段中每个以’- alias’ 开头的一段配置文件都对应一个节点的描述。我们依次来看一下不同类型的节点的描述都包涵哪些内容吧。“
下面是一个数据输入节点的配置,这是一个系统工具。
# 系统工具loaddata, 原始数据输入节点
- alias: 输入序列文件 # 展示在主站工作流详情页的图标下方,作为注释
app_id: 55128c58f6f4067d63b956b5 # 该工具在对应域的唯一编号
inputs: null
name: loaddata # 该工具名称
node_id: loaddata_reads # 此工作流中该工具所在节点的唯一编号,可自己命名
outputs:
data:
enid: loaddata_reads # 该节点输出的数据的标识符,可以作为其他需要
# 使用该结果的工具的输入,填在其他工具inputs参数
# 的enid处
parameters: null
我们的工作流借鉴了有向无环图的概念(KEGG pathway中也有类似概念)。工作流开始运行时,每一步都要找到初始节点。初始节点的筛选原则有两条,要么该节点无需依赖其他数据输入,要么该节点依赖的其他节点的数据输入已经完成。inputs是null,说明无需等待其他数据,作为有向无环图的头被定下来,作为工作流的起始点。
该工作流的核心步骤, fastqc 软件,该节点的配置文件如下
# 分析工具节点Fastqc
- alias: fastqc 0.11.3
app_id: 585b73e4534680001aa385c7
inputs:
reads:
- enid: loaddata_reads # 即上述loaddata系统工具outputs的enid
name: Fastqc
node_id: Fastqc_node1
outputs:
tgz: # 该outputs类型是tgz, 该信息通常可以从该工具的
# 配置文件获得
- enid: Fastqc_output_tgz
parameters:
threads: # 分析软件一般都需要指定一些参数,参考app的配置文件
value: 2 # value指明默认值
variable: true # variable的逻辑值指明用户是否可以更改这些参数设置
一个具有多个输入和多个参数的 app 在工作流中 nodelist 部分的写法
# 具有多个输入和多个参数的bwa mem 工具
- alias: bwa mem
app_id: 55f3cd9d5346800017c1e715
inputs: # 该工具接收3个inputs:
# reads, mates, refgenome
reads:
- enid: loaddata_output_reads_1
mates:
- enid: loaddata_output_reads_2
refgenome:
- enid: loaddata_output_refgenome
name: bwa mem alignment
node_id: bwa_mem_align
outputs:
sam:
- enid: bwa_output_sam
parameters: # 该工具可以指定三个参数:
# mark_short_split_hits_as_secondary
# num_of_threads
# read_group
mark_short_split_hits_as_secondary:
value: true
variable: true
num_of_threads:
value: 1
variable: true
read_group:
value: ' '
variable: true
一个存储数据输出的节点在 nodelist 中的写法
# 系统工具,数据输出存储节点
- alias: store Fastqc_output_tgz
app_id: 55128c94f6f4067d63b956b6
inputs:
data:
enid: Fastqc_output_tgz # Fastqc_node1节点的outputs的enid
name: storedata
node_id: store_data_node_fastqc
outputs: null
parameters:
description:
value: ' '
variable: false # 系统工具,取值不可变化
name:
value: ' '
variable: false
Y 叔讲解完,问到:“小 F, 你现在能回答,nodelist是如何规定节点与节点之间的执行顺序吗?或者说,数据是如何在工作流中流动吗?”
小 F:“是通过enid这个字段!只需将数据产生节点的 outputs 的 enid 指给下一个数据处理节点的 inputs 的 enid, 工作流就能识别该按什么顺序连接这些节点。但是,在配置文件内,对每个节点的描述语句块在排列顺序上是没有规定的(例如 python 中 PyYAML library 是把 yaml 格式按 mapping structure 解析,可理解为一种 dict,即按键值对存储,而不是有顺序的list)。”
Y 叔: “很好,小 F, 那你现在知道应该如何让这个工作流可以跑起来吗?”
小F 点点头,在定义 workflow 的配置文件中按上述说明修改好 account , description , 和 name 字段之后,在上述 cfg_workflow.py 脚本中新增为工作流增加定义的一行,并注释掉和初始化有关的代码。
# -*- coding: utf-8 -*-
import gdpy
# 配置个人密钥信息,以访问主站资源时进行签名认证
access_key_id = '<从GeneDock主站个人帐号设置页面获得>'
access_key_secret = '<从GeneDock主站个人帐号设置页面获得>'
# 创建一个签名认证时需要的auth对象
auth = gdpy.GeneDockAuth(access_key_id,access_key_secret)
# 创建一个workflow 对象
workflow = gdpy.Workflows(auth, 'cn-beijing-api.genedock.com', 'fancheng')
# 用 create_workflow() 方法新建一个工作流
#create_workflow_result = workflow.create_workflow('Fantasy007', 1, 'my first boost')
# 用 put_workflow() 方法根据修改后的 Fantasy007_workflow_put.yml 配置文件定义工作流
put_workflow_result = workflow.put_workflow('Fantasy007_workflow_put.yml')
接着,在命令行输入python cfg_workflow.py, 回车
可发现根据包含 nodelist 的配置文件定义工作流后,该工作流系统显示可以运行了。
运行任务
Y 大叔:“此时刚定义的工作流只是确定了各节点的流向,即原始数据依次经过哪些节点/软件/工具分析,最终结果存储在哪个节点上。”

“但工作流此时并不知道本次分析任务的输入文件存放在何处?工作流的某些软件可能在制作工具的时候已经做了一些参数的设置,但我们可能想要更改这些参数,以优化我们的结果或满足特定的需求,这也需要“通知”工作流我们做的改动。”
运行任务配置文件详解
“因此,我们也需要有一个与本次 task 相关的配置文件,规定和说明上述信息。我们还是从 examples 的 task_active.yml 文件讲起。”
# 运行工作流Fastqc的配置文件
Conditions:
schedule: ''
Inputs:
loaddata_reads: # workflow 中别名为"输入序列文件"的节点的
# node_id
...
...
...
Outputs:
store_data_node_fastqc: # workflow 中别名为"store Fastqc_output_tgz"的
# 节点的 node_id
...
...
...
Parameters:
Fastqc_node1: # workflow 中别名为"fastqc 0.11.3" 的节点的
# node_id
...
...
...
Property:
CDN: # Content Delivery Network 服务,用来传输图片,
# 影片,应用程序等文件,未来可能变化,无需特别更改
required: true
reference_task:
- id: null # 运行前请确保此 id 值设置为 null
water_mark: # 图片是否加上水印,未来可能变化,无需特别更改
required: true
style: null
description: <Please input the task's description in here>
name: <Please input the task's name here> # 合法的命名应只包含字母,数字,短横线'-', 下划线'_'
# 合法的命名中不应包含空格
# 合法的命名以字母开头
# 合法的命名不包含中文
# 合法的命名长度在3-128个字符以内
# 若您不填写,则会在运行任务时由系统自动以工作流名加上时间戳
小 F 说:“这回我能看懂了。Inputs 下面是跟数据输入节点有关的描述。Outputs下是跟数据输出,存储节点有关的描述。 Parameters下是跟数据分析有关的节点信息。但是我有些疑惑,这和我们在定义工作流时的相关节点描述时有哪些区别呢?”
Y 叔: “好问题,我们先来看 Inputs. 相对于工作流的配置文件强调定义 node 之间的连接关系,即每个节点的 enid, run task 时对每个节点更多指明它们属性上一些信息。如 Inputs 的 loaddata_reads 节点下,除了 data 标签下指明了输入文件的存放路径,还有 formats 标签说明有效的,该工作流支持的文件格式;maxitems 和 minitems 指定的允许输入的文件个数范围;required 的逻辑值明确该参数是否必须;以及 type 标签指定的该输入项类型是文件。对 Outputs, 与此类似。”
上述 Inputs 部分的完整配置
# run task 配置文件Inputs部分
Inputs:
loaddata_reads:
alias: 输入序列文件
category: loaddata
data:
- enid: null
name: public:/demo-data/WES-Germline_NA12878_smallsize/NA12878-NGv3-LAB1360-A_1000000_1.fastq.gz # <== 需改为自己的数据的路径
# 路径格式为 <account name>:<file path>/<file name>
# <account name> 为该数据所属于的帐号名,如平台的公共数据,则帐号名是"public"
# 或贵公司/机构私有的数据,则account 是注册时帐号名 "YourCompanyname"
property:
block_file:
block_name: null
is_block: false
split_format: default
formats: # format, maxitems, minitems, required,
# type 等字段可参考接收该输入的节点Fastqc的app
# 配置文件
- fq
- fastq
- bam
- gz
- sam
maxitems: 1000 # 允许包含文件最大数目
minitems: 1 # 允许包含文件最小数目
required: true # 是否必须
type: file # 文件类型
若有多个输入项, 依次写多个节点配置即可
Inputs:
loaddata_reads_1:
<describe attributes of the node, such as format, type, items numbers and so on>
...
...
...
loaddata_reads_2:
<describe attributes of the node, such as format, type, items numbers and so on>
...
...
...
loaddata_refgenome:
<describe attributes of the node, such as format, type, items numbers and so on>
...
...
...
Outputs 详细填写内容
# run task 配置文件Outputs部分
Outputs:
store_data_node_fastqc:
alias: store Fastqc_output_tgz
data:
- description: <Please input the description of the output data in here>
name: /home/admin/Fastqc_test/store_data_node_fastqc.tgz
# <== 填写个人数据路径, 只有文件名则默认存 /home/admin 下面
# 为防止遗忘,可按照 Inputs 类似 <account name>: /home/admin/<your path>/<your file>
property:
block_file:
block_name: null
is_block: false
split_format: default
formats:
- tgz
maxitems: 1
minitems: 1
type: file
Parameters 详细填写内容
# run task 配置文件Parameters部分
Parameters:
Fastqc_node1:
alias: fastqc 0.11.3
parameters: # <== 参考该工具配置文件每个参数的属性
threads:
hint: Specifies the number of files which can be processed simultaneously. Each
thread will be allocated 250MB of memory so you shouldn't run more threads
than your available memory will cope with, and not more than 6 threads on
a 32 bit machine。
maxvalue: 16
minvalue: 1
required: true
type: integer
value: 2
variable: true
运行任务程序代码
# -*- coding: utf-8 -*-
import gdpy
# 配置个人密钥信息,以访问主站资源时进行签名认证
access_key_id = '<从GeneDock主站个人帐号设置页面获得>'
access_key_secret = '<从GeneDock主站个人帐号设置页面获得>'
# 创建一个签名认证时需要的auth对象
auth = gdpy.GeneDockAuth(access_key_id,access_key_secret)
# 创建一个投递任务所需的task对象
task = gdpy.Tasks(auth, 'cn-beijing-api.genedock.com', 'fancheng')
# 确定本次运行任务所依赖工作流及自定义参数
active_workflow_result = task.active_workflow(<Your task configuration file name, e.g. 'task_active.yml'>, <The workflow name you wish to run, e.g.'Fantasy007'>, <The workflow version you wish to run, e.g. 1>)
执行上述代码前后发生的事情
执行代码前任务报告的情况,可知此时我们的任务还不存在

执行代码前数据页面的情况,还没有我们指定的存放 Fantasy007 的结果的存在
任务投递后等待运行过程中

开始运行后的数据页面出现我们指定的存放数据的文件夹
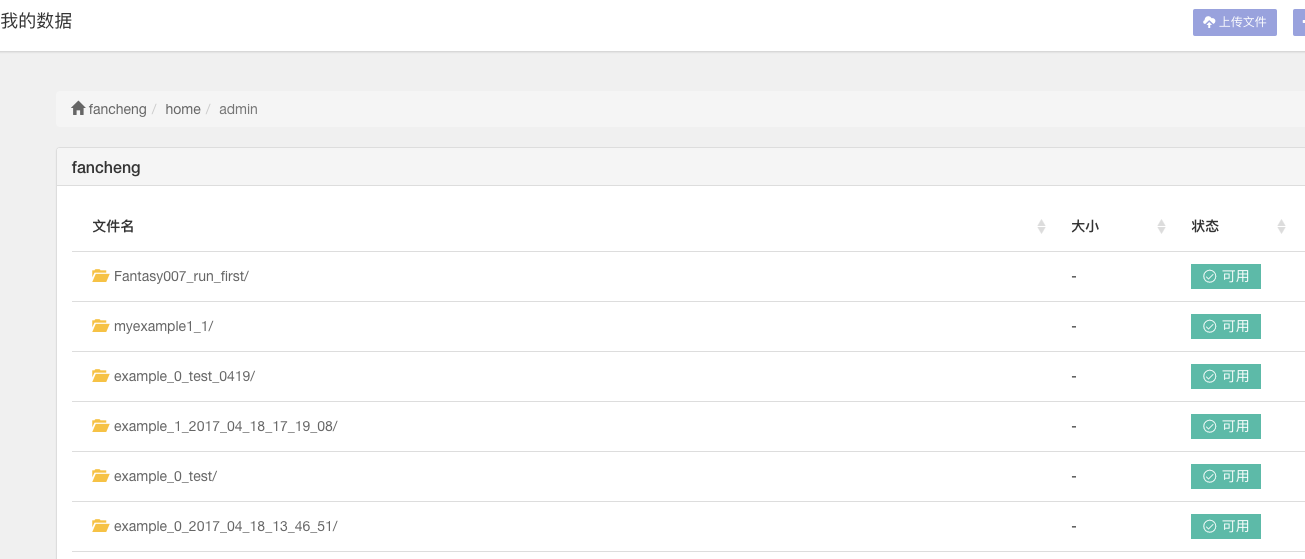
该任务对应的文件夹 Fantasy007_run_first/ 下面,可以看到任务在等待或进行中的时候,显示的是“上传中”。

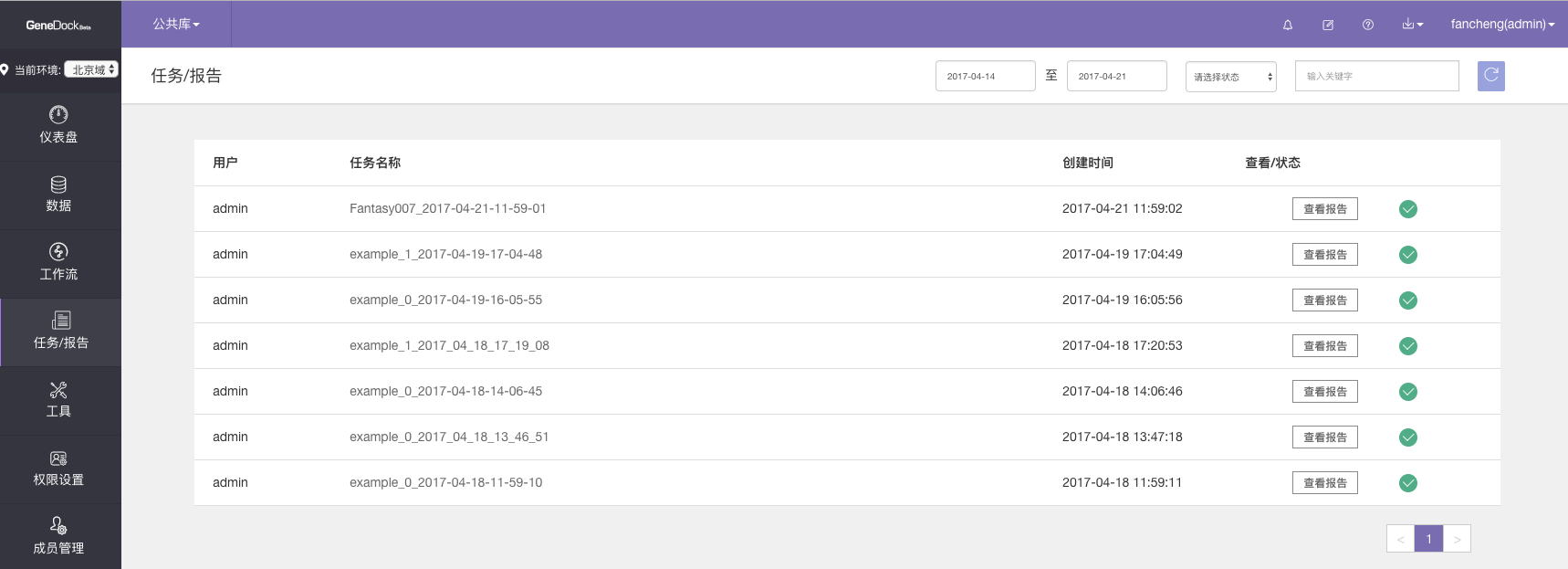
用SDK投递的任务成功运行后“任务/报告”页面的情况
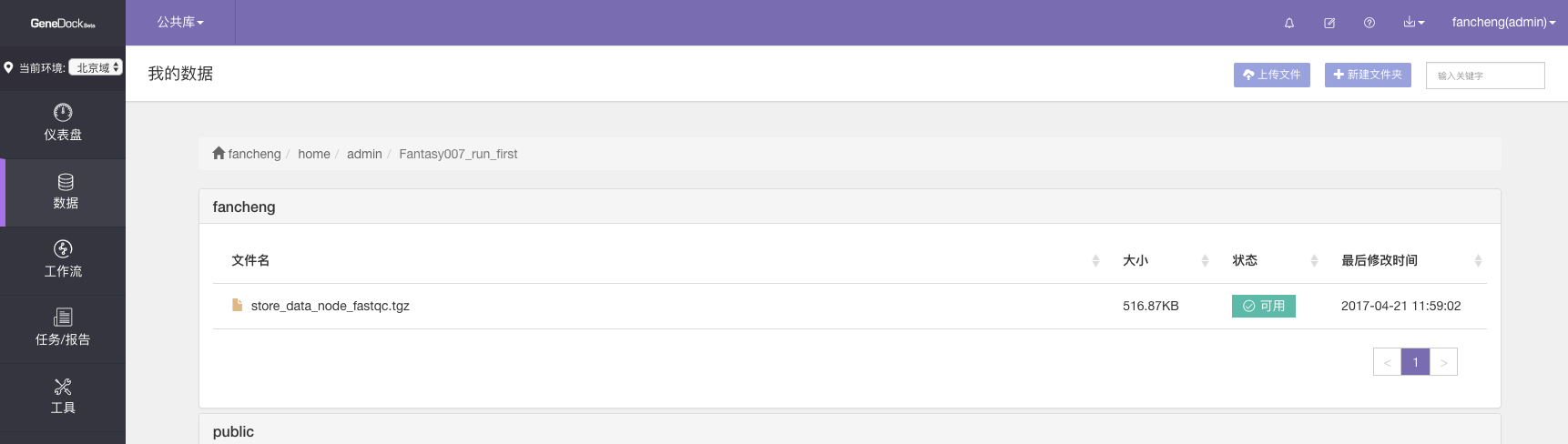
用SDK投递的任务成功运行后”数据”页面的情况
道可道,非常道:active_workflow()究竟干了什么
小 F 并不满足于仅跑通任务, 继续询问 Y 大叔到道: “我在官网的 Python SDK 使用手册 ActivateWorkflow 部分,除了上面的从 workflow 生成一个 task 的代码,下面还有两行。”
# 小 F 看到的剩下的代码
print active_workflow_result.task_id
print active_workflow_result.task_name
” 我试了一下,分别得到了一串字符串,和我在配置文件中name字段为运行的任务取的名字。这串字符串和这个任务在任务/报告页面的地址栏中末尾的编号是一样的,应该就是 task id 吧。但是 active_workflow() 方法得到的返回对象,就是 变量active_workflow_result 的具体内容,我还不是很清楚。 为什么它可以 查看 task_id 和task_name呢? 它是否还能查看别的属性呢?“
590828775346800025a7cf8d
understand_gdpy_return_object-01
“ 小 F 对 task id 的理解很正确。为了回答你的问题,我们看一下active_workflow() 方法中是如何操作的吧。”
“ 我们打开下载的文件夹下 gdpy/api.py 这个文件。看一些 Tasks 这个类下面 active_workflow() 相关的代码。小 F, 看了这段代码, 你有什么启发吗?”
# api.py 定义的 Tasks 类中 active_workflow() 方法
class Tasks(_Base):
...
...
...
def active_workflow(self, param_file, workflow_name, workflow_version, workflow_owner=None):
"""
usage::
>>> resp = task.active_workflow('workflow_param_file', 'workflow_name', 'workflow_version')
"""
...
...
...
try:
data = dict()
data["parameters"] = yml_utils.yaml_loader(param_file)
data["workflow_name"] = workflow_name
data["workflow_version"] = int(workflow_version)
data["workflow_owner"] = workflow_owner
data["task_name"] = data["parameters"].get("name")
super(Tasks, self).__init__(self.auth, self.endpoint, 'tasks', self.timeout)
resp = self.__do_task('POST', '', data=data)
except ValueError as e:
raise e
return ActiveWorkflowResult(resp)
“我知道这个返回值肯定和 ActiveWorkflowResult() 这个函数有关。可是我找遍了 api.py 这个脚本, 都没有找到对这个函数的定义呢?”
“如果一个函数没有在脚本内定义,又不是 built-in 函数,那它还有什么办法可以获得呢?”
“想到了,可能是通过从别的模块调用!看这个脚本调用的模块里面, json 模块是和处理 json 格式有关的一个模块。time 是与时间有关的模块。剩下的模块应该都是 SDK 中自己定义的。 defaults 里面定义了一些和利用 requests 模块请求 API 有关的全局变量。http 模块是对 requests 请求模块的一些封装。yml_utils 与处理 yaml 格式有关。exceptions 是与异常处理有关。 utils 是与查看版本,处理系统时间有关的一些小命令。compat是与格式转换有关的模块。看上去可能定义这个模块的就只剩 models 了。 ”
# api.py 调用的模块
import json
from . import defaults
from . import http
from . import yml_utils
from . import exceptions
from . import utils
from .compat import urlparse, to_unicode, to_string, to_json
from .models import *
import time
“很好,那我们来看一下 models 这个模块吧。你知道这个模块在哪里吗?”
“就在和 api.py 的同级目录 gdpy/下面。我打开看看。。等等。。 这里! 这里面(models.py)果然有 ActiveWorkflowResult() 诶!但是说实话,Y 叔, 其实我基本上看不懂。 我平时都是写Perl的, 虽然 Perl 是支持面向对象的,但我平时编程基本就是按做一件事的过程来的,一二三,最多写个函数。这些类啊,方法啊,属性啊,真是全然不懂。刚才知道要看 ActivateWorkflowResult(), 只是因为 return 这个关键字很熟悉。”
...
...
...
def _bget(body, key, converter=lambda x: x):
body = json.loads(body)
if key in body:
return converter(body[key])
else:
return None
...
...
...
class ActiveWorkflowResult(RequestResult):
def __init__(self, resp):
super(ActiveWorkflowResult, self).__init__(resp)
# task 名称
self.task_name = _bget(self.response.text, 'task_name', str)
# task id
self.task_id = _bget(self.response.text, 'task_id', str)
“不要怕,并没有想象那么复杂。其实你每天都在和类及对象打交道。举个例子,你迟到了,打个出租车去上班。如果按你以往的编程习惯,可能会写出 turnleft(), goStraight500Meter(), turnright()这样一系列函数,描述你从家到公司这个过程。但一旦你搬家了,或者从机场去公司,这个线路变化了,那么所有的代码就都要重写了。”
“但是作为一个乘客,你其实只需要和司机这一个对象打交道。你上车,告知司机目的地,付款,下车。你作为一个个体,有很多个人特征,每一个特征都是你的一个属性:年龄,眼睛的颜色,你想去的地方。可能司机师傅很健谈,也会关心你的年龄这个属性,关心你成长的烦恼。但对于把你送到目的地这件事而言,他其实只需要知道你的一个属性,即本次旅程你想去的地方,就可以了。”
“为了获得你的这个属性,司机这个对象向你发来一个请求 ask_destination(), 你为了把你本次的目的地答复给他,便调用自己的 reply_destionation() 这个方法,获得目的地的具体值。”
“司机和你都是对象。你们彼此通过一些方法交互。记住,几乎没有孤立存在,完全不需要和其他对象交互的对象。”
“下面以我们所关注的 ActiveWorkflowResult() 做例子, 具体看一下这个面向对象的过程在 Python 语言中的实现。类似定义一个函数一样,用 class 加类名定义了一个类。def 定义了一个函数,__init__ 是一种特殊的方法,作用是初始化一些属性。super()超类这个概念略复杂,我们以后再去谈它。”
“self 指的是这个对象自身,小圆点后可以理解为这个对象的属性。从这段代码看, ActiveWorkflowResult 至少有两个属性,task_name 和 task_id。它们在 __init__ 函数中通过 _bget() 函数的赋值被初始化。_bget() 函数之所以看上去这么奇怪, 前面有一个下划线, 是因为这表示它是 models 模块私有的。”
“为了看懂 _bget() 函数,我们重新看一下刚才的 api.py 的代码。 这段程序使用了 try/except 捕获异常。 首先它会执行 try 语句块中的内容, 如果没有发生错误,则顺利执行完毕,返回 ActiveWorkflowResult(resp) 的值。如果遇到错误,特别是 Python 中 ValueError 这类的错误, 程序便会抛出异常并终止。”
“具体来看 try 语句块执行的代码究竟做了什么事情。 在上面提到的奇怪的超类 super() 之前, 基本上都在初始化 data 这个字典。例如 parameters 这个键的值是通过 SDK 中 yml_utils 模块的 yaml_loader() 方法处理我们刚才讲的运行任务有关的配置文件得到的。 我们在运行的 python 脚本中给 active_workflow() 传的第二个参数,需运行的工作流的名称和第三个参数,需运行的工作流的版本号,分别被传给了 data 的键 workflow_name 和 workflow_version. 如果运行的不是自己配置的工作流,或是公共的自己有权限的工作流,而是别人私有的,那么,还需指定 workflow_owner 这个参数,这一次因为我们的工作流都是自己创建的,我们暂不考虑这种情况。task_name 这个键是根据我们写的配置文件解析出来的,不用另外传参。”
“最为关键的语句就是下面这句。这一次我们先不去看 __do_tasks() 具体的实现。参数 data 就是我们上面初始化的字典,那么参数 POST 让你想到了什么呢, 小 F ?”
resp = self.__do_task('POST', '', data=data)
“我在你们主页的 API 文档 <a href=”https://www.genedock.com/article/docs/seqflow/developer/api/workflow/Workflow 相关/#ActivateWorkflow”-target=”_blank”>ActivateWorkflow 看到过。这部分的请求语法就是用的POST。”
“没错。你可以了解一些 Python 的 requests 库相关的知识。我们用 post() 操作向我们的平台发送了一个请求。请求的资源地址是按 /accounts/<account_name>/projects/<project_name>/tasks/构成的, 请求体(body)的内容即我们用 data 字典确定的。”
“而返回的对象,通常可以用.text属性查看。如果是json格式的返回对象,也可以用 .json()方法查看。我们对requests做了一些封装,所以是.response.text”
print active_workflow_result.response.text
“ 从 API 文档响应示例和打印该对象的 text 属性, 都可以看到该返回对象有 task_id 和 task_name 两个属性”
{"task_name": "understand_gdpy_return_object-02", "task_id": "59082b025346800024a7d0f6"}
尾声
小 F 谢过 Y 大叔, 开心地回去找主任汇报这几天的进展。 主任说: “不错嘛,年轻人就是掌握新事物快啊。但这个好像也只是一次分析一组数据,离你说的要做流行病学研究,成百上千次分析,好像还差得很远?”
小 F 说: “我最近和肿瘤科的生信分析师小 W 一起就GeneDock 的Python SDK交流很多,她在这方面很有心得,我去找她再学几招。”
主任: “好,过几天再听你的好消息。”
附录
更多详细信息和指导,请参考官方 Python SDK 手册。
本文着重介绍使用 GeneDock Python SDK 配通一个分析流程,并运行任务的具体方法,包括这个过程中的一些相关概念和原理的理解。故对配置工作流需要串联的工具的制作,包括测试数据的传输,未作详细深入描写。这些部分内容请参阅 GeneDock 官网相关文档。
运行工作流时任务的命名规范
“name: “ 后,以合法的字符组成的字符串(字母,数字,短横线,下划线), 无论是否用单引号将字符串引用起来,都不影响正确运行(事实上 yaml 中字符串不需要引号将其引用)
若不填写任何字符,即解析 “name: “ 后的字符是 null, 系统会自动按该任务所依赖的工作流名加时间戳命名并运行(时间,工作流名间都以下划线,短横线连接,没有空格等非法字符,可发现也是符合命名规范的)
若是 ‘ ‘ (单引号内空格) 或仅单引号,会报 “ the input task name is invalid! “ 的错误自己撰写yaml配置文件,或使用本文未提到的 GetTool, GetWorkflow, GetTask 等方法获得的配置文件做模版复制粘贴过程中,需特别注意每个字段的缩进。
因为yaml格式是按照缩进规定层次的。如运行任务的yaml中 Inputs 部分,data 这个 list, 含有 enid, name, property 三个 key; 若复制粘贴时不小心将 name 和 property 向前缩进两个空格,
则 parser 会认为 name 和 property 是和 data 一样属于 loaddata_reads 这个 node 属性的 key, 则会由于系统无法识别而报 “ Internal server error! “关于更多类和对象的例子, 可参考 Matt Weisfeild 著《面向对象的思考过程》(The Object-Oriented Thought Process) 第四版
关于 requests 更多请求的操作及返回对象的解析,可参考 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html